extract()
Extracts the text value from selected data: a node path, column, or rectangular region, depending on the type of data source.
This method always returns a String.
extract(left, right, verticalOffset, regionHeight, separator)
Extracts a value from a position in a text file. Coordinates are expressed as characters (horizontally) or lines (vertically).
left
Number that represents the distance, measured in characters, from the left edge of the page to the left edge of the rectangular region. The leftmost character is character 1.
right
Number that represents the distance, measured in characters, from the left edge of the page to the right edge of the rectangular region.
verticalOffset
Number that represents the current vertical position, measured in lines.
regionHeight
Number that represents the total height of the region, measured in lines.
separator
String inserted between all lines returned from the region. If you don't want anything to be inserted between the lines, specify an empty string ("").
"<br/>" is a very handy string to use as a separator. When the extracted data is inserted in a Designer template, "<br/>" will be interpreted as a line break, because <br/> is a line break in HTML and Designer templates are actually HTML files.
Examples
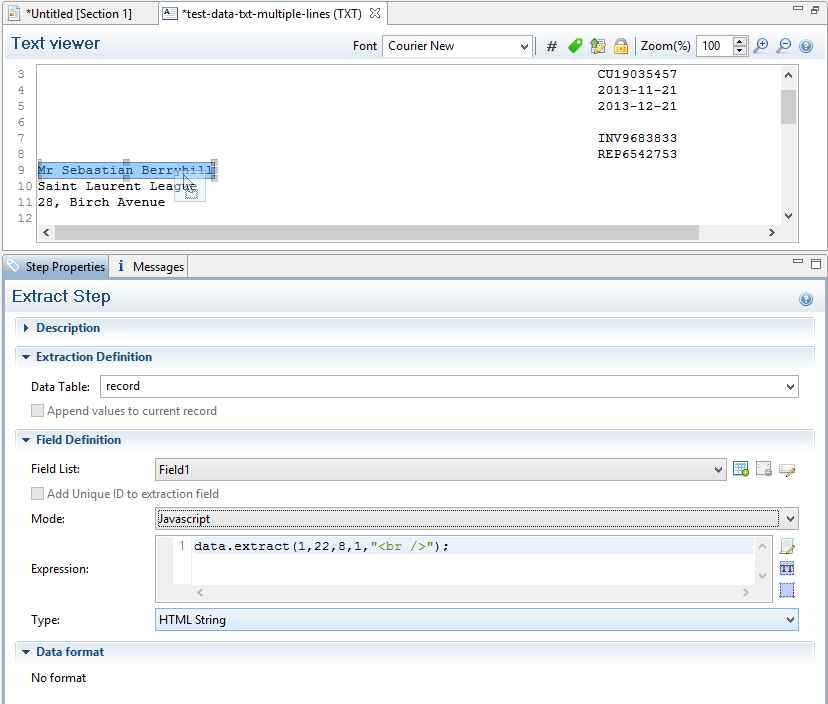
Example 1:
The script command data.extract(1,22,8,1,"<br />"); means that the left position of the extracted information is located at character 1, the right position at character 22, the offset position is 8 (since the line number is 9) and the regionHeight is 1 (to select only 1 line). Finally, the "<br/>" string is used for concatenation.
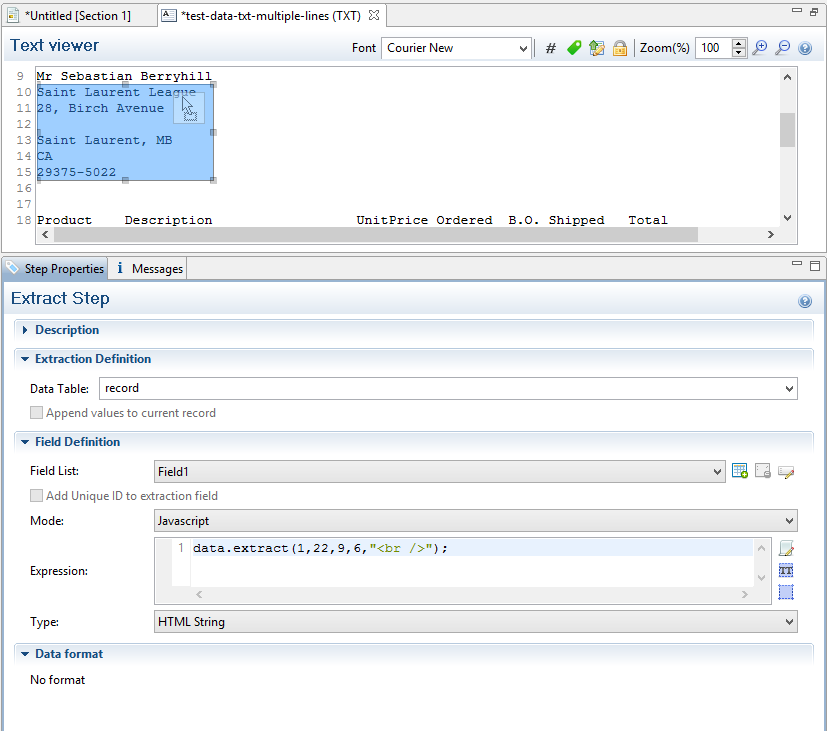
Example 2:
The script command data.extract(1,22,9,6,"<br />"); means that the left position of the extracted information is located at 1, the right position at 22, the offset position is 9 (since the first line number is 10) and the regionHeight is 6 (6 lines are selected). Finally, the "<br/>" string is used for concatenation.
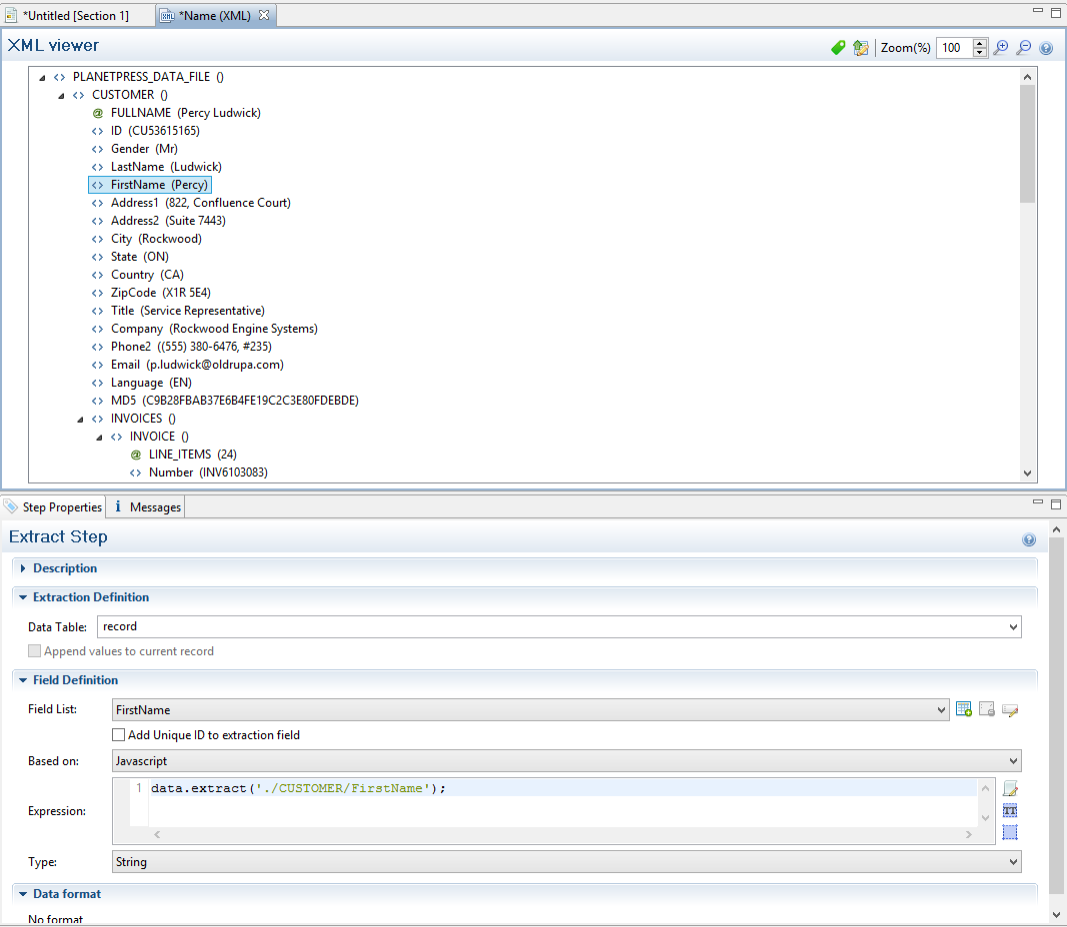
extract(xPath)
Extracts the text value of the specified node in an XML file.
xPath
String that can be relative to the current location or absolute from the start of the record.
Example
The script command data.extract('./CUSTOMER/FirstName'); means that the extraction is made on the FirstName node under Customer.
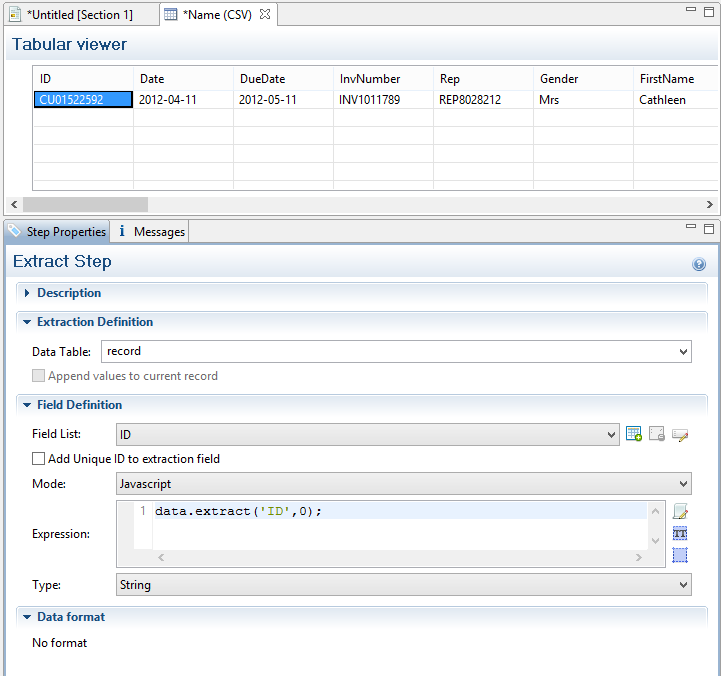
extract(columnName, rowOffset)
Extracts the text value from the specified column and row.
columnName
String that represents the column name.
rowOffset
Number that represents the row index (zero-based), relative to the first row in the record. To extract the first row, specify 0 as the rowOffset.
Example
The script command data.extract('ID',0); means that the extraction is made on the ID column in the first row.
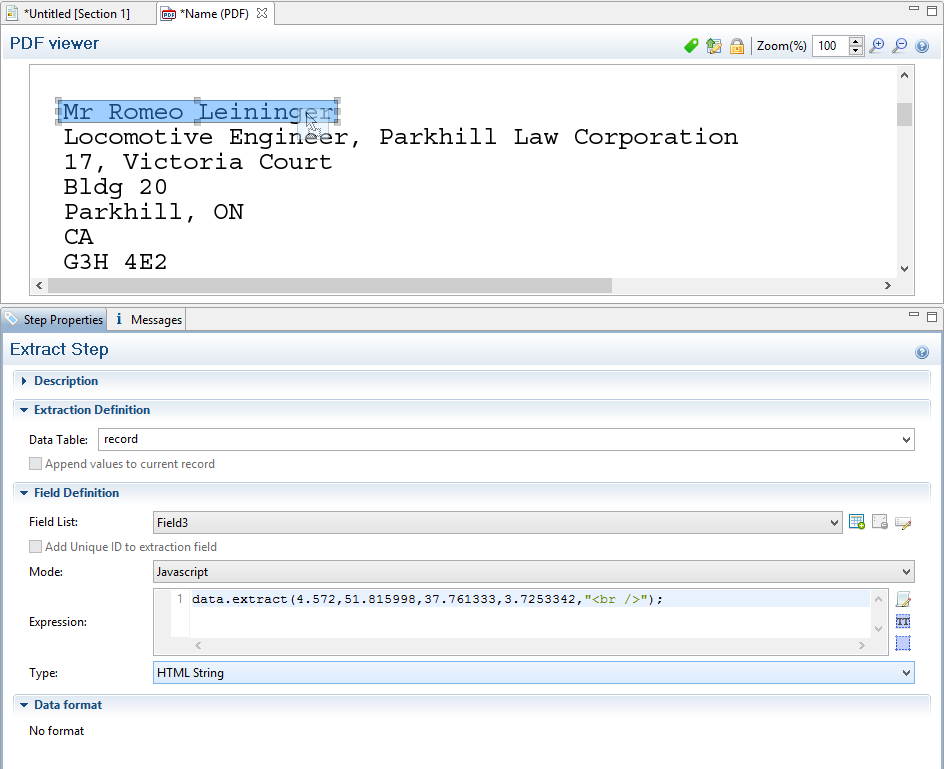
extract(left, right, verticalOffset, lineHeight, separator)
Extracts the text value from a rectangular region in a PDF file. All coordinates are expressed in millimeters.
left
Double that represents the distance from the left edge of the page to the left edge of the rectangular region.
right
Double that represents the distance from the left edge of the page to the right edge of the rectangular region.
verticalOffset
Double that represents the distance from the current vertical position.
lineHeight
Double that represents the total height of the region.
separator
String inserted between all lines returned from the region. If you don't want anything to be inserted between the lines, specify an empty string ("").
"<br/>" is a very handy string to use as a separator. When the extracted data is inserted in a Designer template, it will be interpreted as a line break, because <br/> is a line break in HTML and Designer templates are actually HTML files.
Example
The script command data.extract(4.572,51.815998,37.761333,3.7253342,"<br />"); means that the left position of the extracted information is located at 4.572mm, the right position at 51.815998mm, the vertical offset is 37.761333mm and the line height is 3.7253342mm. Finally, the "<br/>" string is used for concatenation.