The PlanetPress Capture (PP-Capture) library is an application programming interface (API) that allows access to the entire functionality of PP-Capture. Its objects can be used from any ActiveScript environment (such as the Run Script task in PlanetPress Workflow) or any other language that can access IDispatch-enabled interfaces in a type library.
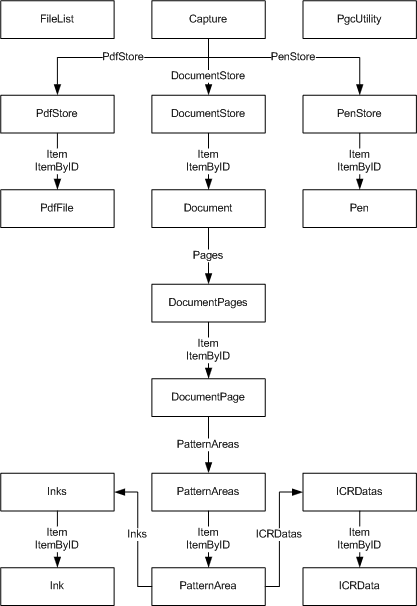
The API is rooted in the Capture object. To create a new Capture object, use the CaptureLib.Capture ProgID. This object exposes several data stores: the Document Store, the Pen Store and the PDF Store. In addition, a PgcUtility object, used to work directly with PGC files without having to deal with the standard PP-Capture workflow, and a FileList object, used as a parameter for some methods, are also available.
- Note:
- Only the Capture, PgcUtility and FileList objects can be created. Other objects are obtained by calling API methods.
The Document Store contains the logical structure of documents, pages, pattern areas and inks. The physical pages are stored in PDF files located in the PDF Store, where a single PDF may contain pages from several documents. As long as they are in the database, documents are virtual only; they do not exist as a single file entity.
As inks are captured from licensed pens, the Document Store is updated with the PGC files containing the inks. Although a document may be generated and saved as a new PDF on disk at any time, typically this would be done when a documents is closed (i.e. all the ink-related conditions are met). A saved document contains the pages from the original PDF as well as the inks, added as an optional layer.
The backend of the API is the Capture database. The Document Store, the PDF Store and the objects representing their content are all abstractions for one or more table or records in the database. The database is accessed via ODBC. It may reside on the local computer but may also be located on a remote computer.
Design Considerations
The fact that the persistent storage is a database introduces a tradeoff. On one hand, minimizing the number of requests to the database reduces the latency, i.e. the time it takes for an API call to complete. On the other hand, reducing the number of requests means that more data is transferred during each of these requests, thus increasing latency. In other words, the choice is betwee few, big requests or several small requests. In addition to that, the database is a moving target because its content can change at any moment.
Therefore, object properties are not requested until the object is actually retrieved. For example, the attributes of a page from a document are not requested until this page is accessed. Conversely, once the object is created, its properties are not refreshed until the object is recreated.
The consequence of this is twofold. First, one can never assume that a value is stable. For example, the return value of Capture.DocumentStore[42].Pages[3].PatternAreas.Count may change if called repeatedly. In fact, Capture.DocumentStore[42] may even refer to a different document!
Second, because data access is live, using an object member of another object to access its properties means that the properties are requested every time. In other words, doing
w = Capture.DocumentStore[42].Pages[3].Width;
h = Capture.DocumentStore[42].Pages[3].Height;
ends up requesting the list of pages from the 43th document and the properties of the fourth page twice.
Because of this, the number one rule when working with the Capture API is pointer reuse. In other words, the code above should be written as:
p = Capture.DocumentStore[42].Pages[3];
w = p.Width;
h = p.Height;
The second important rule is to use an object's ItemID whenever possible. Every time an item is accessed by index, the list of ItemIDs must be requested, and then i-th ItemID is taken from the list and used to retrieve the object's properties. Using ItemIDs instead of indices speeds up access as the index-to-ItemID lookup is not required.
While this "everything is live" rule may seem like a big drawback, in the real-world it is seldom an issue. Except for documents, which are discussed below, things don't change often. A single document will never be created by two threads simultaneously. And once it is created, except for adding inks, a document is actually invariable. Therefore, the probability of having a conflict, for example working on a document while its page count changes, is next to zero.
The one exception to the "everything is live" rule is the Document Store. The Document Store downloads the list of document ItemIDs at the time it is created and keeps this list in memory. This is done for two reasons. First, it simplifies the implementation of the Find method, which filters the documents that are available through a specific instance of the Document Store. Second, it allows looping through the documents without fear of getting a "List Index Out of
Bounds" type of error, at the cost of showing outdated information. For the same reason, operations on objects that don't exist anymore in the database silently fail.
